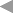
1.2 Basic Components of a
DYABOLA Database
|
|
|
Title text
|
|
Record number
|
|
Descriptors
|
|
|
|
Database tree (father-child)
|
|
References (general)
|
|
Forward reference (link)
|
|
Reference back (aquired-Link)
|
|
|
|
Classifier tree (subject)
|
|
Headings
|
|
Key-words
|
|
|
Titles
The titles are the most important
components of a DYABOLA database. They are the smallest possible
independent units of information. All other components are made
up of several titles, describe relationships between such titles,
or depend on a title. The title itself consists of three elements:
a title text, a record number and the descriptors.
The title text functions as
a designation. It can just as easily be the name of a person,
a date, or a longer grave inscription. It is possible to prepare
different "types of title text", in order to distinguish between
different axiomatically separate natural phenomena. As a general
rule these are, for example, objects, persons, places, time concepts,
events, sources, pictures and literature.
The record number is necessary as
a clear identification number, since different titles can of course
have the same title text. Just think of common names like "Smith,
J." or the paratactic "columns" of an early Christian basilica
(whose position in the nave is a descriptor and does not belong
in the title text). The record number does not necessarily appear
for the user; however, if, for example, he or she noted down the
record number after an earlier search, it can be used to get directly
to an ambiguous title.
The descriptors fill a title with
meaning. There are two main types of descriptor: the reference
and the dependent descriptor. Both have the function of specifying
the title. The following example will show the purpose of the
descriptors: In his memory, man distinguishes between two objects
with the same name not according to a classification or record
number, but according to accompanying information or circumstances.
One thus identifies two anonymous column capitals in the pantheon
(both have the title text "capital" in the CENSUS) according to
their position in the portico; two churches with the name "San
Marco" conjure up an image in our minds in relation to their location,
such as Venice or Rome. In the first case, the descriptor is designed
to be a dependent descriptor, as there is nothing more to say
about the position "front left". However, "Rome" and "Venice"
are linked to "San Marco" by means of a reference, as they are
themselves titles to which more information is attached that has
nothing to do with "San Marco". For example, Rome can be the location
of other churches. |
Relations between titles
A single title does not constitute a database.
The dataset of a DYABOLA database consists of numerous titles
that are related to each other in different ways. Two main types
are to be distinguished: sequential-hierarchic and hypotactic.
The sequential-hierarchic relations hold the whole database together,
and make it into a conceivable set of data, the "database tree".
By means of the hypotactic "references", one title can be connected
to any other title, similar to the way it is done in the Internet.
The database tree arises from the fact that each title
can have a "father" and many "children". In the ideal case, this
leads to a single tree which has the name of the database as its
uppermost title (e.g. Census of Antique
) and branches off downwards
via various different subdirectories (such as monuments, documents
),
if necessary down to the capitals of a large spa or the quadrants
on a codex page. The database tree can be used to present all
conceivable hierarchic structures.
The references make it possible,
to link any particular title with any other particular title,
as already mentioned. However, the DYABOLA cross-reference has
two decisive advantages over the hyperlink in the Internet, namely
it has a clear condition and, if desired, an automatic reference
back.
A link is inserted by the operator, for example by filling
in the "Artist" field under "Object". The operator then looks
for the "Person" concerned and makes this selection. The link
"Person to Object" under the condition "Artist" has thus already
been defined by the database administrator beforehand. This kind
of cross-reference always relates to two types of title text (see
title text), such as object and person in our example. Of course,
two titles with the same type of title text can also relate to
each other (for example "Person to Person" under the condition
"Father/Mother").
An aquired link is automatically
assigned after a link has been inserted. It must be defined once,
but separately by the database administrator, because, in contrast
to the link, it can have a different name and is not necessarily
desirable in all cases. For example, in the aquired link "Person
to Object", the different name would be "Works" instead of "Artist".
A case in which the reference back is not desirable would, for
example, be details of the author in the object dataset. It is
good to be able to cite the person entering an object, but it
generally makes no sense to fill the details of a person who can
also appear as an author of a few interesting monographs with
tens of thousands of object datasets. |
Dependent descriptors
The dependent descriptors designate
the amount of all non-independent descriptors, i.e. all those
that are not themselves a title and relate to a reference to the
first title. There are two types of dependent descriptor: the
"heading" and the "key-word". The latter depend on the former
and, whereas the headings must be defined by the administrator,
new key-words can be assigned to a heading by the operator.
The classifier tree (subject) is
a compilation of all conditions. In principle, it is a tree of
headings which branch out downwards. The headings and key-words
of a database are visible to the researcher, but the tree also
contains the entire control of the program invisibly. At the same
time, headings of the visible part can also refer to headings
in the invisible part (e.g. types of title text).
The headings are specified dependent
descriptors predefined by the administrator. Like a title, headings
can have a "father" and several "children". For purposes of differentiation,
one speaks here of levels of the classifier tree, since it functions
as the foremost father. Depending on the type of dependent descriptor,
it must be decided whether the entry to be made is entered as
a heading or as a key-word. Typical headings are specified, particularly
hierarchic concept systems, such as the categories of a library
system, a classified thesaurus such as Icon-Class, or a clearly
limited number of object locations in a museum. In addition, headings
can refer to other headings, in order to open up areas of a database
which are actually not accessible to the researcher.
The key-words are appended to headings
of the classifier tree in the form of lists. The name of the respective
key-word list is that of the respective heading. The key-words
of a list can relate to each other. This makes it possible, for
example, to make reference to a synonymous term. |
Comments
Comments are independent text fields
that can be inserted at different points in the program. They
can be used, for example, to more precisely explain a heading
in the classifier tree or further specify a descriptor in the
title. The comments behave like the title text in relation to
the title. They are freely composed texts that can consequently
be searched through with the free-text search. |
|
|
|
|
|
|
copyright 2001 by Verlag Biering & Brinkmann
|
|
Postfach 45 01 44, D-80901 München
|
|
|
|
|
|